Tobit模型
- ##### 分析方法视频解读:
- ##### 案例数据下载
在某些情况下,被解释变量Y的取值范围会受到限制,比如研究家庭医疗保险支出的影响因素时,某此家庭没有医疗支出即数字全部为0,也或者研究家庭收入水平时,某些样本家庭完全没有收入那么收入就全部为0,也或者数据调查中有一项为收入为10万以上,那么10万以上的具体数据就‘截尾’(没有10万以上,最多就到10万),又比如研究存款的影响因素,但是有的样本存储为负数(即其为负债非存储),诸如此类,按常理应该是正常的正态数据,但是其被解释变量出现‘断层’(删失),均可使用tobit模型进行研究(而不是常用的ols线性回归)。
- ##### 特别提示
- 删除数据分为两类,分别是‘左删失leftcensor’和‘右删失rightcensor’。上述中小于等于数字0即为左删失,10万即为右删失;
- SPSSzero 默认支持左删失和右删失的设置,如果不设置,则其完全等于普通ols线性回归。
Tobit模型案例
- #### 1、背景
当前有一项关于工资影响因素的研究,被解释变量为ln工资,解释变量为年龄,是否结婚(数字1代表结婚,数字0代表未结婚),子女数量,受教育年限共4个。被解释变量ln工资为工资取对数,如果没有工资则为数字0。明显的,类似这样的数据应该使用ols线性回归,但考虑到数据中有很多工资为0(即没有工资),此时就可考虑使用tobit模型更加适合。为更加方便的查看被解释变量的数据分布情况,将ln工资作直方图如下:
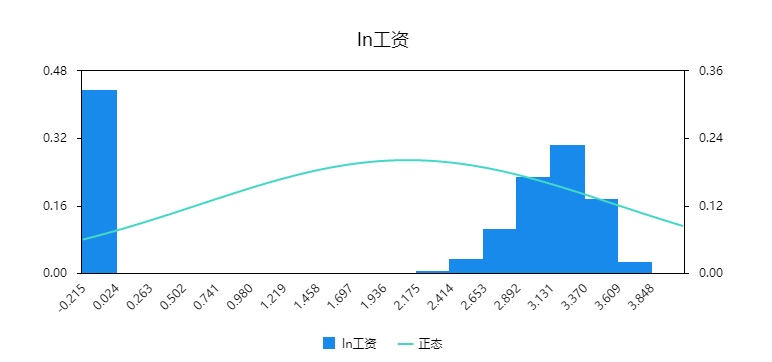
从上图可以明显的看到,数字出现删失,即有一部分数据集中在数字0。当然在分析的时候可考虑筛选出数字大于0的数据再进行ols线性回归也可(但这样做会减少样本利用率),如果说筛选出ln工资大于0后再做直方图如下:
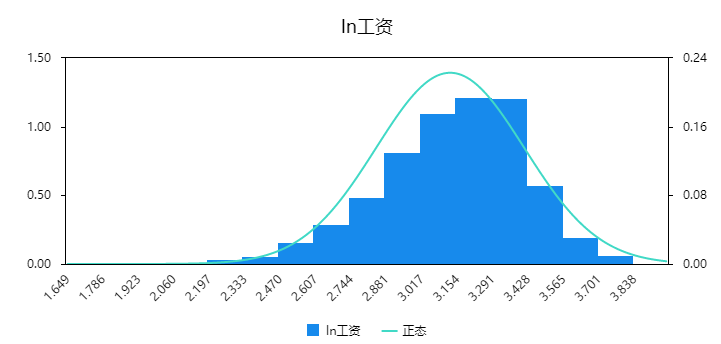
明显的可以看到,筛选出ln工资大于0的数据,其明显的服从正态分布,使用ols线性回归非常适合。正因为此,tobit目的在于解释‘删失或受限’的数据情况。本案例使用tobit回归模型研究年龄,是否结婚,子女数量,受教育年限共4项对于ln工资的影响情况。
- #### 2、理论
Tobit回归模型用于解决‘删失/受限被解释变量’这种问题,如果被解释变量中的数据有出现‘删失/受限’,此时进行ols回归并不科学。删失分为两种,分别是‘左删失leftcensor’和‘右删失rightcensor’,如果说小于等于某个数字的数据‘不正常’(左删失leftcensor),也或者大于等于某个数字的数据‘不正常’(右删失rightcensor),此时均可使用Tobit模型。
- #### 3、操作
本案例操作截图如下:
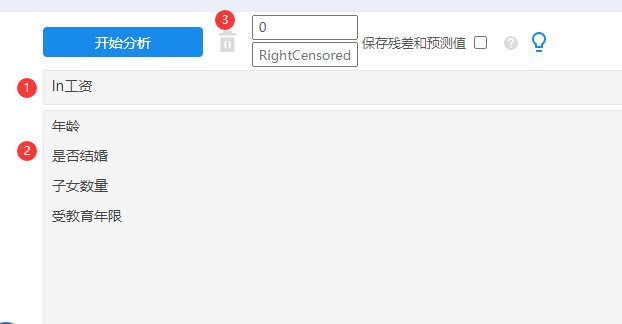
本案例中有左删失数据,且leftcensor为0,因此在‘LeftCensored’中输入数字0,本案例数据并没有右删失值,因此不设置‘RightCensored’。
- #### 4、SPSSzero 输出结果
SPSSzero共输出4类表格,分别是Tobit回归模型似然比检验,Censor数据样本汇总,Tobit回归分析结果汇总和Tobit回归分析结果汇总-简化格式。说明如下:
| 表格或图 | 备注说明 |
|---|---|
| Tobit回归模型似然比检验 | Tobit模型的似然比检验结果 |
| Censor数据样本汇总 | 删失数据具体情况展示 |
| Tobit回归分析结果汇总 | Tobit回归模型的表格结果 |
| Tobit回归分析结果汇总-简化格式 | Tobit回归模型的简化表格结果 |
- #### 5、文字分析

上表格展示Tobit回归模型似然比检验结果,其一般用于判断模型是否有意义,原理上Tobit模型使用极大似然法进行计算,因而可对似然比检验结果进行关注。从上表可知,似然比检验的p值为0.000<0.05,即说明放入4个解释变量对于模型有帮助,即说明模型构建有意义。
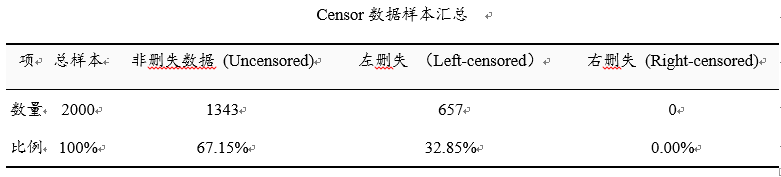
上表格展示删失数据的分布情况。共有2000个样本,本案例设定左删失leftcensor为数字0,上表格展示出共有657个样本为左删失数据(即在657个样本数据小于等于数字0),比例为32.85%,没有设置右删失rightcensor,则没有右删失数据。
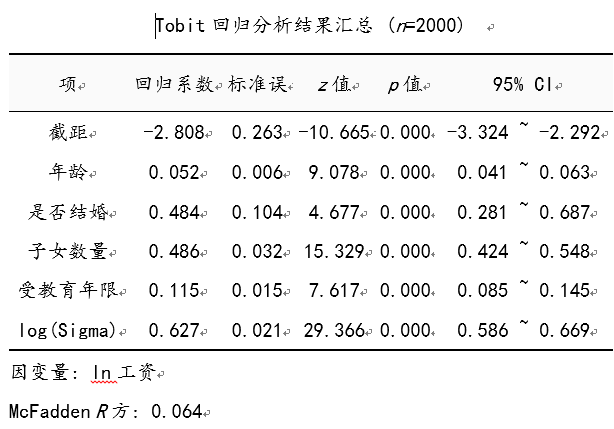
上表格展示出tobit回归模型拟合结果。模型公式为:ln工资 = -2.808 + 0.052年龄 + 0.484是否结婚 + 0.486子女数量 + 0.115受教育年限。模型的McFaddenR方为0.064,即意味着4个解释变量对于工资的解释力度为6.4%【特别提示:通常情况下对此指标的关注度较低】,最终具体分析可知:
年龄的回归系数值为0.052,并且呈现出0.01水平的显著性(z=9.078,p=0.000<0.01),意味着年龄会对工资产生显著的正向影响关系,年龄越大工资越高。是否结婚的回归系数值为0.484,并且呈现出0.01水平的显著性(z=4.677,p=0.000<0.01),意味着是否结婚会对工资产生显著的正向影响关系,即相对未婚群体,已婚群体的工资明显更高。子女数量的回归系数值为0.486,并且呈现出0.01水平的显著性(z=15.329,p=0.000<0.01),意味着子女数量会对工资产生显著的正向影响关系,子女数量越多的群体工资收入越高。受教育年限的回归系数值为0.115,并且呈现出0.01水平的显著性(z=7.617,p=0.000<0.01),意味着受教育年限会对工资产生显著的正向影响关系,即受教育年限越多的群体工资收入会越多。
总结分析可知:年龄, 是否结婚, 子女数量, 受教育年限共4项均会对工资产生显著的正向影响关系。

上表格展示出Tobit回归模型的简化结果表格,该表格列出模型的关键信息点,可直接使用。
- #### 6、剖析
涉及以下几个关键点,分别如下:
- 提示‘没有uncensored数据’,如果设置leftcensored或rightcensored后,导致未删失数据个数为0,则会出现此提示。
涉及以下几个关键点,分别如下:
- ###### Tobit回归时的模型似然比检验不通过,显示模型无意义?
- Tobit回归模型用于解决有删失数据的样本,当然也可考虑使用ols回归(此时不考虑删失数据这一问题),与此同时,也可考虑先筛选过滤掉删失数据,然后再进行ols回归。建议可对比ols回归和tobit回归的结果,综合进行判断。
- ###### McFaddenR方非常低?
- Tobit回归时McFaddenR方的意义相对较小,一般不用过多关注此指标。
- ###### TOBIT回归SPSSSAU与Stata结果出现不一致?
- spsszero 进行tobit模型时使用极大似然法估计,迭代次数和收敛标准不完全一致容易出现结果的数字不一样;
- 出现此种情况时,通常是在数据质量不太好,比如多数变量均不显著的情况下;
- 出现结果数字不一样,但结论正常情况下完全一致,这种情况是正常的,不同的软件均有可能出现此种gap,这是由算法自身导致正常现象。
- 更多说明原理说明可点击查看
- ###### 如何进行DEA-TOBIT模型?
- SPSSzero进行DEA分析时,选择保存效益,然后使用OE值进入TOBIT模型即可,OE值介于0~1之间,一般左删失设置为0,右删除设置为1即可。
![]()